[论文解读] DistServe分离式架构优化大模型推理服务性能
Ping Zhou, 2024-05-05
这是一篇北大和UCSD合作的论文,主题是优化大模型推理服务的性能。
在前文(RWKV)中提到过,对于大语言模型(LLM)来说,更大的挑战是推理。因为推理成本属于OpEx,用户使用越多,花费就越大。降低LLM的推理服务成本,是LLM应用在商业上可持续的关键之一。
LLM推理服务对性能的要求,也与训练有所不同。推理服务更注重响应的延迟,由于直接面向用户,响应延迟直接影响用户体验。例如对于聊天机器人类型的应用,需要尽快的开始回答,也就是说要尽快生成输出第一个token,之后的token,需要能跟上人的阅读速度;而对于代码生成类的应用,则需要更快的端到端生成速度,以支持实时的代码提示。
目前的大模型推理服务系统,都是以吞吐(throughput)为标准来优化的,也就是单位时间服务的用户请求数(request per second, rps)。这个指标,也被用作推理成本优化的一个目标,因为更高的吞吐,意味着可以用更少的GPU时间服务更多的用户请求。
作者提出,简单的用吞吐作为指标是不够的。在实际场景中,应用对推理服务有不同的质量目标(service level objectives, SLO),对于LLM推理服务而言,最重要的有两个SLO:
- TTFT (Time To First Token): LLM生成第一个token需要的时间
- TPOT (Time Per Output Token): LLM生成两个token之间的平均延迟
显然,TTFT表示LLM多久开始回答,而TPOT表示LLM的语速。
作者认为,LLM推理服务的质量应该看Goodput,可以理解为“有效吞吐”。Goodput的意思是: 对于每个分配的GPU,在满足SLO目标的前提下(例如 90% TTFT < 200ms,90% TPOT < 50ms),所能达到的最大吞吐。更高的Goodput,意味着每个请求的服务成本更低。
maximum request rate that can be served adhering to the SLO attainment goal (say, 90%) for each GPU provisioned – higher per-GPU goodput directly translates into lower cost per query.
更高的throughput,并不一定意味着更高的goodput。
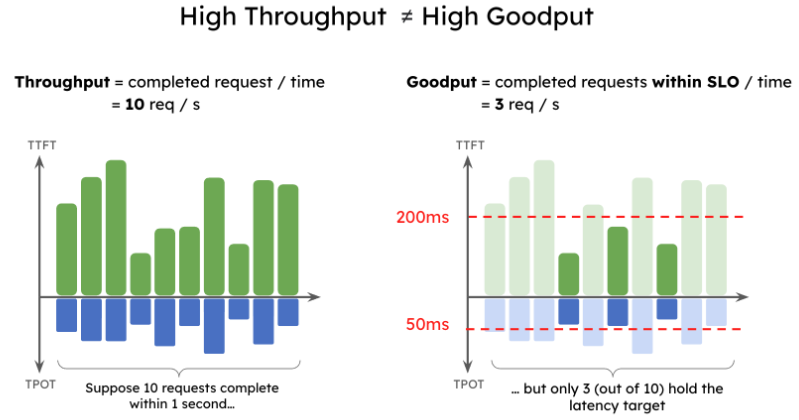
为什么生成第一个token会花费更久呢?
因为在服务用户的时候,LLM需要把用户的历史对话作为上下文,加上用户当前的问题(请求),作为prompt去推理,因此生成第一个token需要计算很长的prompt。而后续的token,因为LLM推理普遍采用KV cache缓存前一次生成的中间结果,避免重复计算,每次生成token计算量要比第一个token小得多。
关于KV cache,简单说几句:不要把它混淆为Key Value,这里的KV指的是Transformer的K,V矩阵。KV cache的原理是,自回归的LLM在生成时,每次生成的上下文,和上一次生成只差一个token,因此有大量计算是重复的。如果把上一次生成时的中间结果(主要是K,V矩阵)记下来,那么下一次生成的时候就可以避免重复计算,大大降低推理成本。这个技术目前已经是标配了,基本上所有的LLM推理都会用到它。
所以,我们可以把整个推理分成2个阶段,生成第一个token的这个过程,叫做prefill,因为在生成第一个token的时候,推理引擎会填充KV cache,而之后的生成过程,称为decode阶段。
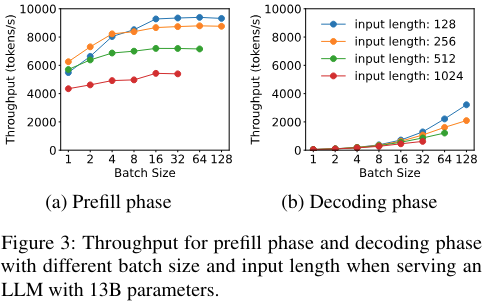
prefill和decode这两个阶段,对计算的需求是很不一样的:
- prefill阶段计算密集,往往较小的batch就能打满GPU,增加更多的batch并不能提高性能;
- decode阶段则相反,计算量小,需要更高的batch来充分利用GPU。
如果按现有的方式,两个阶段都在同一个GPU集群里做,会造成几个问题。
prefill和decode互相干扰:当一个GPU同时处理batch里的多个请求时,如果一个请求在decode,另一个在做prefill,两者会互相干扰,导致时延增加。
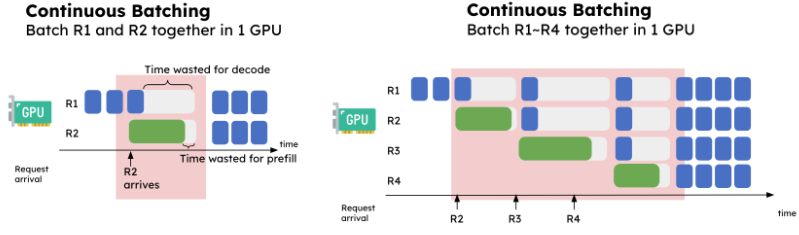
prefill和decode放在一起,另一个问题是导致它们的资源分配和并行策略耦合。前面说过,prefill和decode对计算的需求很不一样,针对prefill优化的并行策略,对于decode不一定适用,反之亦然。例如,当TTFT要求比较高,而TPOT要求较低时,prefill阶段会采用张量并行来达到较低的延迟,而decode阶段更适合数据并行或流水线并行来提高吞吐。把它们放在一起,导致无法采用各自最优的策略。
作者提出的解决方案叫做DistServe,也很容易理解,一句话就能概括:把prefill和decode分离,分在两个集群里做,在prefill集群里生成第一个token,然后把KV cache内容传送到decode集群,进行后续的生成。
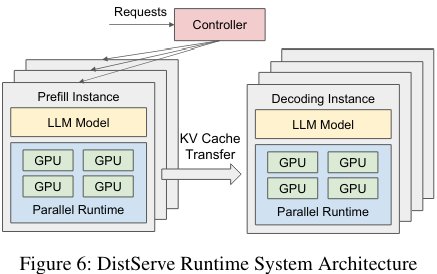
对,就是这么简单。
效果也很显著,与baseline (vLLM)相比,采用DistServe后,单位Goodput提高了2倍到4.5倍。这意味着可以用更少的GPU达到同样的性能,显著节省了推理成本。
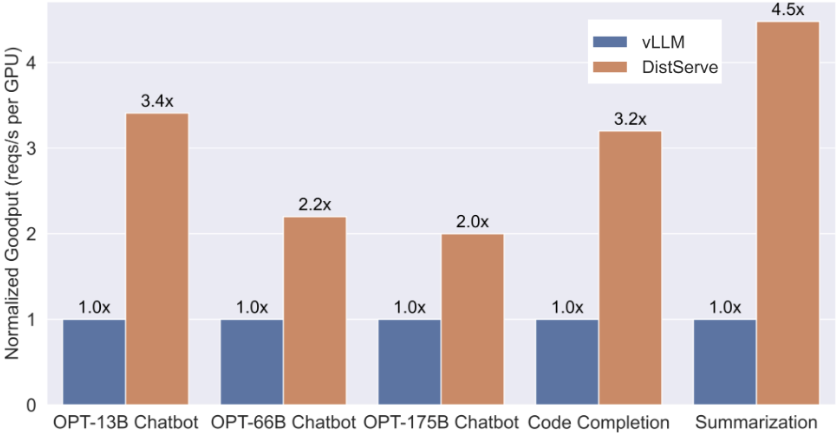
类似的idea,在splitwise, TetriInfer等论文中也有采用,同时作者也在和vLLM社区合作,将这个方案集成到vLLM生态中去。
总结:DistServe找到了LLM推理场景里一个非常有意义的问题,并提出了简单有效的解决方案,效果也很显著。我预测这个idea可能会类似KV cache那样,成为LLM推理服务系统的标配之一。
References: