超长上下文+无分词器,新一代大模型架构?Meta最新论文MegaByte解读
Ping Zhou, 2023-06-10
今天来解读一下 Meta 的这篇论文:MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
大模型的上下文窗口瓶颈
基于 Transformer 的大语言模型,有个很重要的指标就是上下文长度。这是因为模型本身是无状态的,它在推理时只能“记住”上下文窗口里的内容。因此我们在和模型对话时,需要把对话的历史(上下文)和我们的提示一起发给模型,否则模型就只能看到提示本身。随着对话的进行,这个上下文会越来越长,当超过模型的上下文窗口长度时,模型就只能“忘记”最早的对话内容了。
例如在下面这个会话里,如果我们把上下文窗口的长度设为 10 个 token,可以看到模型就不能记住之前对话的内容了:
User> Hi, my name is Ping
AI> Hello Ping, it's nice to meet you! My name is OpenAI.
How can I assist you today?
User> What is 1+1?
AI> The answer to 1+1 is 2.
User> What is my name?
AI> I'm sorry, I don't have access to that information.
Could you please tell me your name?
上面这个例子只是文本对话,对于多模态大模型而言(例如视觉大模型),输入的序列长度可以达到几百万个 token,因此上下文长度对于多模态大模型有极其重要的意义。但是,目前基于 Transformer 的大模型,普遍都只支持几千个 token 的上下文长度。
这是因为,Transformer 的计算成本,是和上下文长度高度相关的。每个 Transformer 模块,都包含 Self-Attention 和 Feed Forward Network (FFN) 两个主要的计算部分:
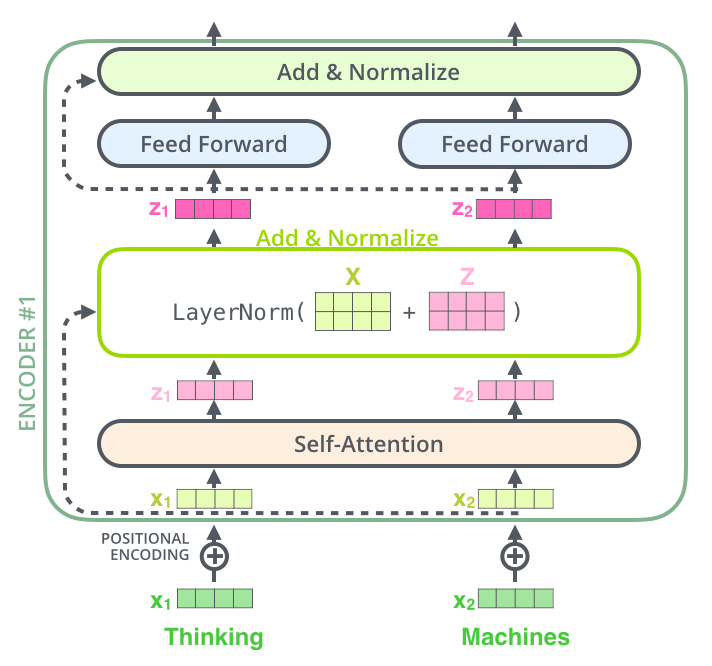 (图源:https://jalammar.github.io/illustrated-transformer/)
(图源:https://jalammar.github.io/illustrated-transformer/)
其中:
- Self-attention 部分,计算量和上下文长度的平方成正比
- FFN 部分,计算量为 2mT,m 为参数数量,T为序列长度(上下文长度)
大模型的参数量巨大,要支持的序列越长,其训练和推理成本也就越高,因此很难 scale 到更长的上下文,比如几百万 token 的长度。
分词器 Tokenizer
除此之外,Transformer 大模型还有一个关键依赖,就是分词器(tokenizer)。
大语言模型在工作时,先要把输入文字分成一个个 token,这里的 token 大致相当于单词(有些分词器也会分成 subword),所有见过的 token 集合就是词汇表 (vocabulary),每个 token 到这个词汇表里查到自己的 id,然后通过 embedding 模型转成一个向量,因此输入序列就是一串向量,每个向量对应一个 token。这里就带来几个问题:
- 这个分词器和大模型是分离的,例如你如果到 HuggingFace 上看,很多模型在用的时候需要指定一个外部的 tokenizer。
- 每个分词器的实现不同,不同的分词器对模型的性能会有影响。
- 由于自然语言本身的模糊性,一段话可能有不同分词方法,有时候分词器需要有领域知识(domain knowledge)才能正确分词。
- 分词器的存在,使得大模型的训练和推理并不是真正端到端(End-to-End)的,这使得大模型的开发和部署都变得更加复杂。
MegaByte 架构解析
解决这些问题,需要在模型的算法和架构上进行创新,Meta 提出的 MegaByte 就是一个最新的尝试。
Overview
简单的说,MegaByte 通过在字节粒度进行分词,摆脱了分词器,又通过多级 Transformer 架构大大降低了模型的计算复杂度,使大模型 scale 到长得多的上下文(百万级)成为可能。不得不说这是一个显著的改进,因此 MegaByte 在发表后很快就得到了 OpenAI 大佬 Andrej Karpathy 的肯定,认为这是一个很有希望 (promising) 的方向:

下面就来分析一下 MegaByte 是怎么工作的。
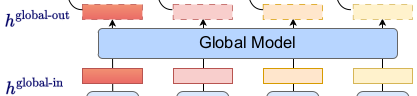
MegaByte 的总体思路很简单,用几句话或者一张图就能概括:
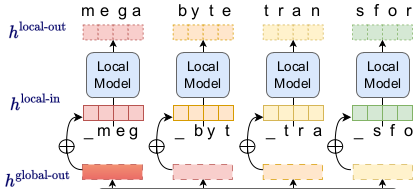
- 输入的序列,按照字节分成固定大小的 patch,可近似看成是经典 Transformer 里的 token,这样就不用分词器了;
- 两级 Trasnformer,一个 Global Model 负责对输入的 patch 序列进行解码(decode),输出同样形状的一串 patch 表示;
- 然后对每个 Global Model 的输出,各自有一个小的 Local Model(也是 Transformer),这个 Local Model 在 patch 里对字节序列进行解码(也就是在 patch 里预测下一个字节);
- Local Model 输出,再经过 SoftMax 预测字节的分布,完成预测。
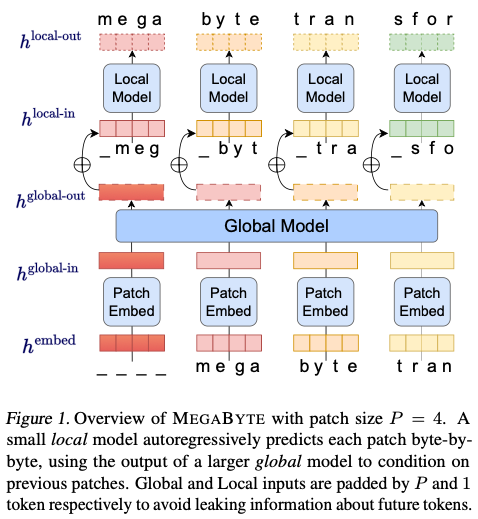
相对于传统的 Transformer,MegaByte 的关键改进有这样几项:
- Sub-quadratic self-attention (次二次自注意力):经典的 Transformer 自注意力的计算复杂度是 \(O(N^2)\) ,而 MegaByte 可以做到 \(O(N^{4/3})\) 。
- 更高效的 patch 前馈网络(Feed Forward Network):经典 Transformer 需要对每个 token 计算前馈网络,在 GPT-3 这样的大模型里,98%的算力(FLOPS)都被用于前馈网络。MegaByte 则不同,它首先在 Global Model 这里,各个 patch 共用一个大的 FFN,然后再在 Local Model 这一级,每个 patch 用一个小得多的 FFN。整体上,在 FFN 的总参数量相当的情况下,MegaByte 的计算量大约是经典 Transformer 的 1/P(P 为 patch 大小)。
- 并行解码(生成):经典 Transformer 在生成时必须顺序执行,一次生成一个 token,因为它是自回归的,本次的输出被用于下一次的生成。而 MegaByte 是并行生成 patch 的表示,生成时的并行度高得多,因此运行(推理)速度也是 MegaByte 的一大优势。例如在作者的实验里,1.5B 参数的 MegaByte 模型,相比只有 350M 参数的 Transformer 模型,其生成速度还要快 40%。这对于降低大模型的推理成本,特别是在端侧的部署具有重要意义。
MegaByte 的关键模块有这样几个,我们结合上面的图逐个分析一下。
Patch Embedder
输入的序列,切成一系列的 patch,每个 patch 大小为 P 字节。这个 patch 序列需要变成 embedding,作为 Global Model 的输入。
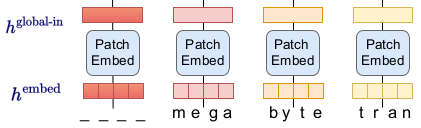
首先,每个字节通过查找 lookup table 变成一个 embedding 向量,这个 embedding 向量的大小(维度)是 \(D_G\) ,然后加上位置编码。
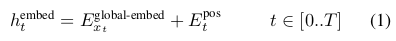
然后,同一个 patch 里的字节 embedding 接起来,就是 patch 的 embedding,因此每个 patch embedding 的大小是 \(P \cdot D_G\) 。
这些 patch embedding 就是 Global Model 的输入。假设 Global Model 的输入序列长度为 K,那就是能接受 K 个 patch embedding, 。
因为是自回归模型,训练时我们会将序列的最后一个 patch 去掉,在序列的第一个位置插入一个“空白”patch,称为 padding embedding (\(E^{global-pad}\)),这个 padding embedding 也是参加训练的。
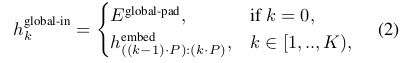
Global Model
Global Model 就是一个普通的 Transformer decoder,它的输入序列长度为 K(K 个 patch),每个 token 就是一个 patch embedding,token 大小(维度)为 \(P \cdot D_G\) 。和普通的 Transformer decoder 一样,计算 patch 之间关系时带上 causal masking,避免出现用将来的 patch 来计算当前 patch 的注意力。
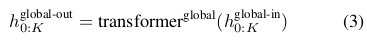
Gobal Model 的输出,是 K 个 patch 的表征(representation)向量,和输入一样,每个输出的 patch 向量维度也是 \(P \cdot D_G\) 。
Local Model
Gobal Model 的输出是 K 个 patch 向量,每个 patch 向量的大小(维度)是 \(P \cdot D_G\) ,需要把 patch 向量按字节切开,也就是切成 P 个大小为 \(D_G\) 的向量,第 p 个字节向量,对应 patch 向量里的维度 \(p \cdot D_G\) 到 \((p+1)\cdot D_G\) 。
然后,上面得到的每个字节向量,还要转换为 Local Model 能用的输入。假设 Local Model 的输入 token 维度是 \(D_L\) ,那么就需要有个 \(D_G \times D_L\) 的矩阵把维度为 \(D_G\) 的字节向量投影成维度为 \(D_L\) 的字节向量。这个投影(转换)矩阵,文中记为 \(w^{GL}\) 。这个投影矩阵应该也是通过训练学习来的(论文中没具体说)。
这样一番操作后,从 Global Model 那儿来的每个 patch 向量就变成了一串维度为 \(D_L\) 的字节向量。
然后,这个 patch 里的每个字节向量,还要加上序列里上一个字节的向量,做法和 Global Model 类似,去掉最后一个字节向量,在第一个位置插入一个 padding embedding (\(E^{local-pad}\))。
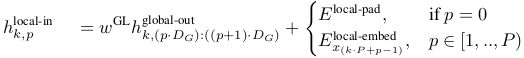
K 个 Local Model 副本,在 K 个 patch 上独立运行,因此在推理和训练时都可以并行,输出是 K 个字节向量序列,每个序列里有 P 个维度为 \(D_L\) 的字节向量,即输出形状为 \(K \times P \times D_L\) 。
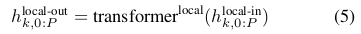
最后,用 Softmax 计算每个位置在词汇表里的概率分布。第 k 个 patch 里的第 p 个字节,对应于整个序列里第 t 个字节,其中 \(t=k \cdot P + p\) 。
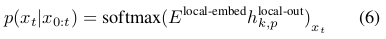
计算效率分析
讨论一下 MegaByte 的计算复杂性。
注意力部分,MegaByte 有 Global 和 Local 两级。
- Global Model 的序列长度是 K(K 个 patch),因此其计算复杂度为 \(O(K^2)\) ,假设输入序列长度(上下文窗口)为 T,每个 patch 大小为 P,那么 K=T/P,因此 Global Model 的计算复杂度为 \(O(\frac{T^2}{P^2})\) 。
- Local Model 一共有 K 个副本,每个的序列长度为 P(patch 大小),因此计算复杂性为 \(O(KP^2) = O(\frac{T}{P}P^2)=O(TP)\) 。
两者加起来,注意力的计算量为 \(O(\frac{T^2}{P^2}+TP)\) 。这里的 P 是一个用户选择的超参数,当 \(P=T^{1/3}\) 的时候,注意力的计算量为 \(O(T^{3/4})\) ,相比经典 Transformer 的 \(O(T^2)\) 复杂度是一个显著的提升。
前馈网络(FFN)部分:实际上大模型计算量主要是在 FFN,例如 GPT-3 规模的大模型,自注意力只占了 FLOPS 的 1.4%。根据 OpenAI 的论文『Scaling laws for neural language models』,前馈网络的 FLOPS 大致可以估算为 \(2mT\) ,其中 m 是模型的非 embedding 参数量,T是序列长度。
MegaByte 有 Global Model 和 Local Model,假设它们的参数量分别为 \(m_g\) 和 \(m_l\) ,那么 FFN 的计算量分别是:
- Global Model: \(2\frac{T}{P} m_g\) ,P为 patch 大小
- Local Model: 每个序列长度为 P,一共有 K 个(K=T/P),所以计算量为 \(2P m_l \times \frac{T}{P} = 2Tm_l\)
加起来总计算量为 \(2T(\frac{m_g}{P} + m_l)\) 。假设 Local Model 远小于 Global Model,即 \(m_l \ll m_g\) ,那么总计算量可以近似为 \(2T\frac{m_g}{P}\) ,也就是经典 Transformer 的 1/P。
这意味着用同样的算力(FLOPS)预算,MegaByte 可以支持大的多的模型,或者反过来,同样的参数量,MegaByte 的算力需求要低得多。
在生成(推理)方面,作者比较了生成每个 patch(近似于 token)的计算量。
- MegaByte: 生成每个 patch 需要经过 \(O(L_{global} + P \cdot L_{local})\) 个操作, \(L_{global}, L_{local}\) 分别是 Global Model 和 Local Model 的层数。
- 经典 Transformer,假设总层数相同,也有 \(L_{global} + L_{local}\) 层,那么生成 1 个 patch 需要经过的操作数为 \(O(P \cdot L_{global} + P \cdot L_{local})\) 。
同样假设 Global Model 层数比 Local Model 大的多,MegaByte 生成一个 patch 经过的操作可近似为 \(O(L_{global})\) ,是经典 Transformer 的 1/P。
注:这里的计算我感觉不太对,经典 Transformer 的序列长度是 token 为单位的,但是论文里的比较都用 T(字节数)作为序列长度来估算 Transformer 的计算复杂度。当然 Transformer 的 token 一般都比较短(word 或者 subword),如果 token 长度远小于 patch 长度的话,那么 MegaByte 在 FFN 和生成上确实能节省不少 FLOPS,但应该没有 P 倍这么多。
变体和优化
除了 MegaByte 的基本架构,因此作者也讨论了一些变体和优化措施。
卷积 patch 编码
作者提到,将序列切分成固定大小的 patch,会带来 translation invariant 的问题。同一段字节序列,在 patch 内不同位置的表征会不同,模型需要重新学习它在不同 offset 的含义。因此作者提出在前面加一个 causal convolution layer,获得 translation-invariant 的上下文表征后,再进行 patch 切分。实验中作者用了过滤器大小 3,5,7 的三层卷积。
跨 patch 注意力
MegaByte 依赖 Global Model 来提取长距离依赖,但是我们也可以在 Local Model 里加入跨 patch 的信息增加上下文。例如,在计算注意力的时候,把上一个 patch 的 r 个 key 和 query 加进来。
Strided Inference
这也是个比较重要的优化。作者发现,每个 patch 中靠近尾部的字节,其 loss 会升高,原因是尾部的预测会更多依赖较弱的 Local Model。作者的解决方法是做 2 次 inference,两次的输入序列相差(offset)半个 patch,然后把 2 次 inference 的前半部分合起来作为最终 inference 的结果,如下图所示。

多模态
MegaByte 的设计目标之一就是多模态,所以作者除了语言模型,还对 MegaByte 在图像和音频上的模型进行了测试,有兴趣的话可以看一下。
伪代码解析
最后看一下论文里附带的伪代码。作者只给出了 forward 部分,而且没有注释,所以我只能根据我的理解猜一下,加上了注释。
class MegaByteDecoder: def __init__( self, global_args, local_args, patch_size, ): self.pad = 0 self.patch_size = patch_size self.globalmodel = TransformerDecoder(global_args) self.localmodel = TransformerDecoder(local_args) def forward( self, bytes, ): bytes_global, bytes_local = self.prepare_input(bytes) global_bytes_embedded = self.globalmodel.embed(bytes_global) # b: batch size # t: 序列长度(patch数, 应该也是local model副本数) # p: patch长度 # e: 每个字节embedding长度 global_in = rearrange( global_bytes_embedded, # 输入形状: # b: batch里有b个序列, # (t p): 每个序列有t*p个字节 # e: 每个字节embeding长度为e # 变换为: # b: batch里有b个序列, # t: 每个序列有t个patch # (p e): 每个patch长度为p*e "b (t p) e -> b t (p e)", p=self.patch_size, ) global_output = self.globalmodel(global_in) global_output_reshaped = rearrange( global_output, # 将输出变成(b*t)个patch,每个patch有p字节, # 每个字节embedding大小e "b t (p e) -> (b t) p e", p=self.patch_size, ) local_bytes_embedded = self.localmodel.embed(bytes_local) local_in = local_bytes_embedded + global_output_reshaped local_output = self.localmodel(local_in) batch_size = bytes_global.shape[0] # local的输出是(b*t)个patch,l应该就是前面的p, v应该就是前面的e? # reshape成b个序列,每个序列有(t*l)个字节embedding x = rearrange(local_output, "(b t) l v -> b (t l) v", b=batch_size) return x # 这个函数将字节序列转成global和local能用的形状,注意这里是字节序列, # 而不是embedding。所以bytes的形状是(b,T)的2维数组,b是batch size, # T是序列长度(字节数) # 返回两个东西: # - bytes_global是bytes同样形状,但是扔掉了最后一个patch,前面插了padding # - bytes_local是(b*t,p)形状,因为这个是给local model用的,每个p字节 def prepare_input(self, bytes): # 看后面的操作,bytes应该是(b,T)的2维数组,b为batch大小,T为序列的长度(字节数) # padding_global形状,应该是(b,p) padding_global = bytes.new(bytes.shape[0], self.patch_size).fill_(self.pad) # 这里就是去掉最后一个patch,前面插上padding bytes_global = torch.cat((padding_global, bytes[:, : -self.patch_size]), -1) # bytes_input形状,应该是(b*t)个patch,每个patch有p个字节 bytes_input = rearrange(bytes, "b (t p) -> (b t) p", p=self.patch_size) # padding_local和padding_global类似,形状是 (b*t, p) padding_local = bytes_input.new(bytes_input.shape[0], 1).fill_(self.pad) # 给local的形状,应该还是(b*t,p),扔掉最后一个,前面插入一个padding bytes_local = torch.cat((padding_local, bytes_input[:, :-1]), -1) return bytes_global, bytes_local
总结和讨论
MegaByte 是一个可扩展的架构,它使 Transformer 大模型能够支持百万级的上下文,并且生成速度也更快。但是目前对 MegaByte 的测试规模还太小,说它能取代经典 Transformer 大模型还为时过早。
另外,序列里如果有连续的空格或者回车,这些也是按原样切成 patch,还是多个空格只算一个呢?我的猜想应该是按原样,毕竟在 Python 里空格个数是很重要的…